

I was looking inside an Android heap dump with YourKit for fun (my definition of fun is 1. rollerblading, 2. baking entremets, 3. poking at heap dumps) and noticed a bunch of stylesheets amongst the top objects dominators, each retaining ~1.5 Mb:
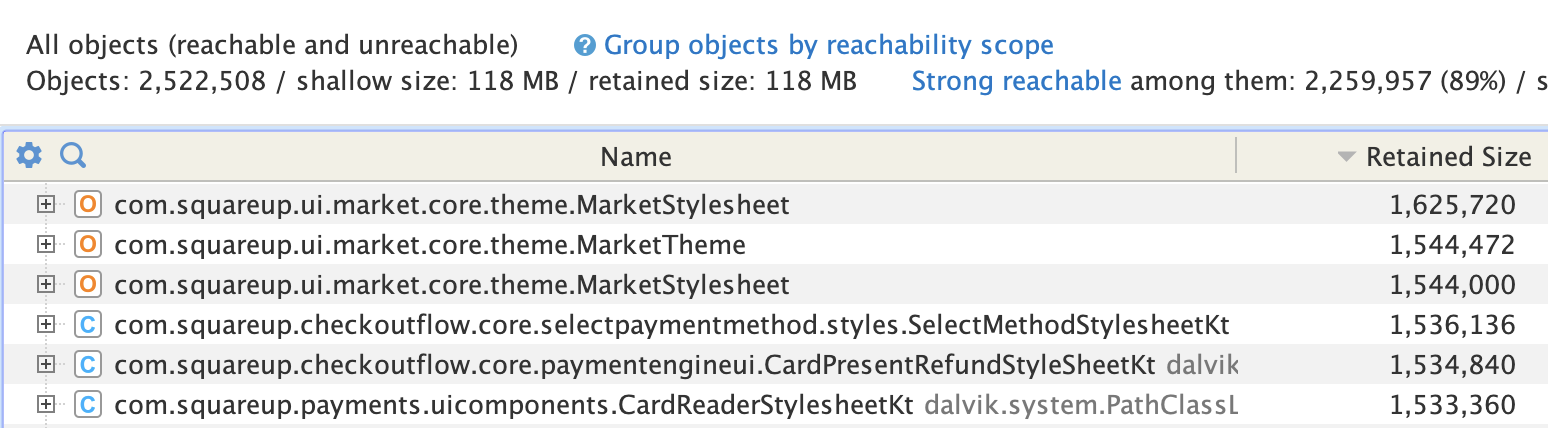
Object dominator... WAT?
In a Java heap, object A dominates object B when every path from the GC roots to B passes through A — meaning removing A guarantees B becomes unreachable and can be collected. The retained size of an object is the total memory that would be freed if it were collected: its own shallow size plus the shallow sizes of everything it exclusively dominates. The shallow size is just the object itself, excluding anything it references.
I opened up one of the stylesheet objects, and noticed they were full of design tokens fields, each token itself defining numerous MarketRamp objects, each with a size of 792 bytes.
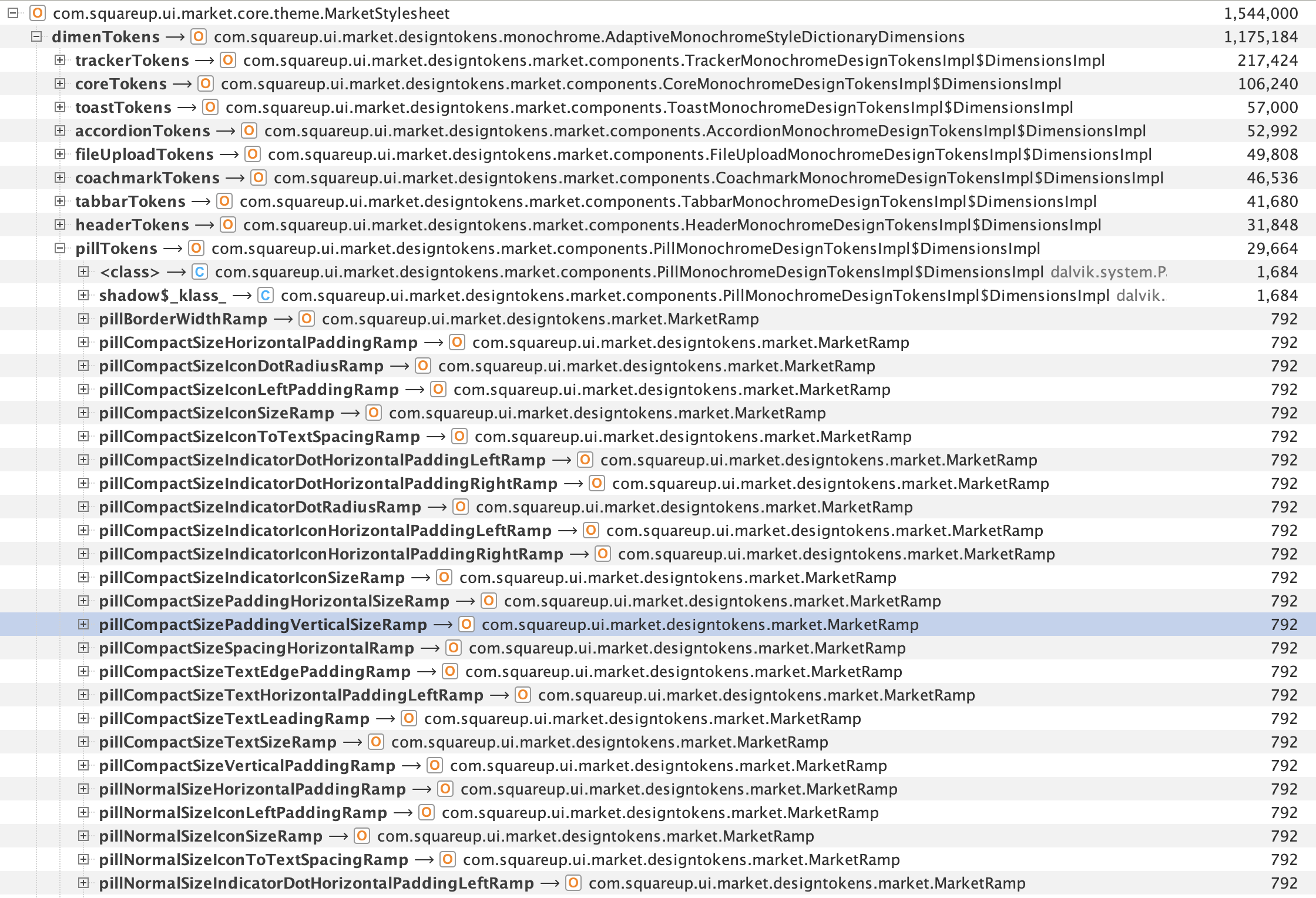
I looked at how many instances of MarketRamp we had in memory: 24,674. They all retain exactly 792 bytes, which makes for a total retained size of 19.5 Mb:
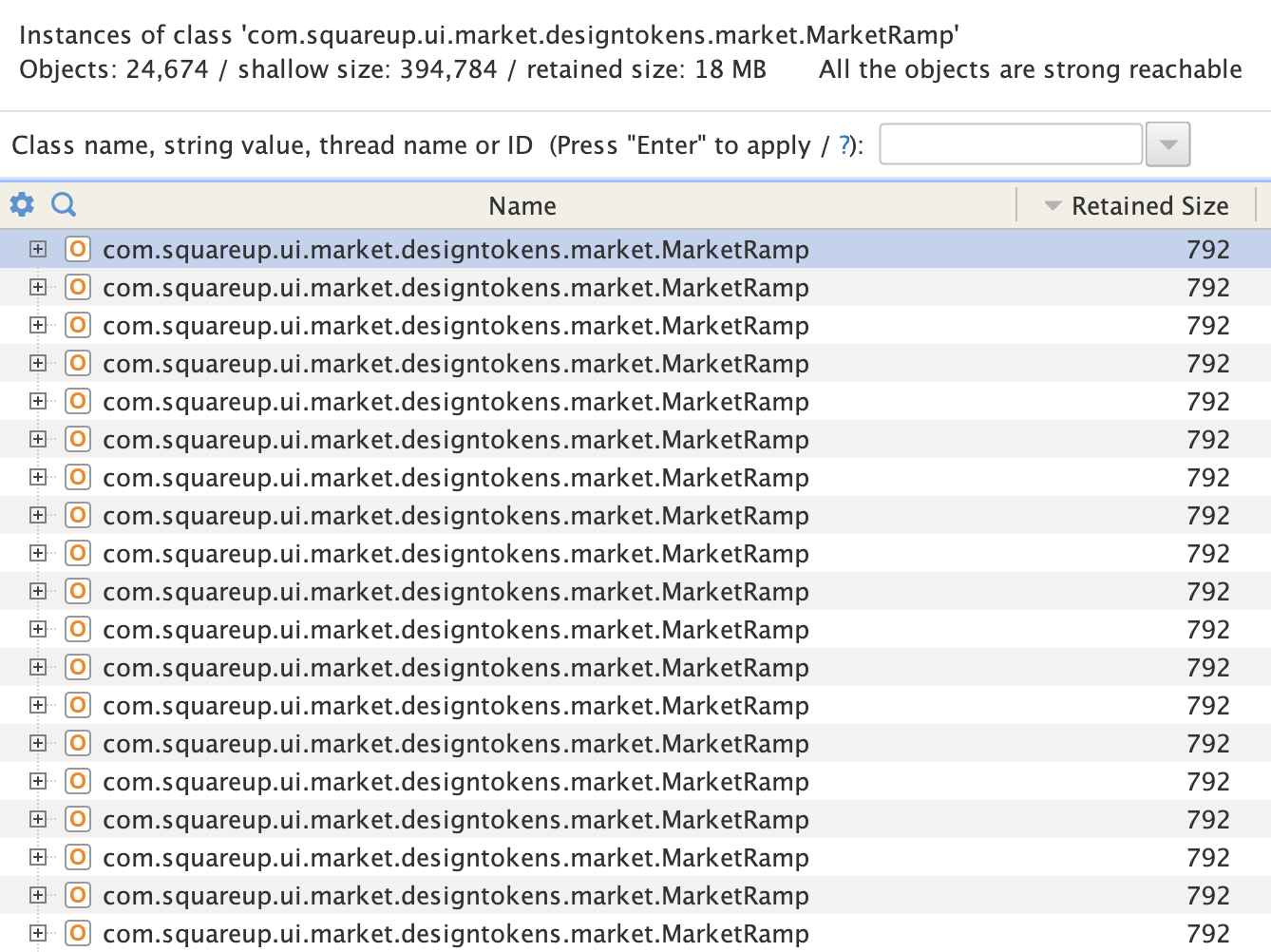
792 bytes doesn't feel like a lot, I would never have thought to look deeper if it wasn't for the large number of instances. So, what are all those bytes for?
Turns out, 776 out of the 792 bytes are for a HashMap that associates 12 "RAMP" enum values to a corresponding float:
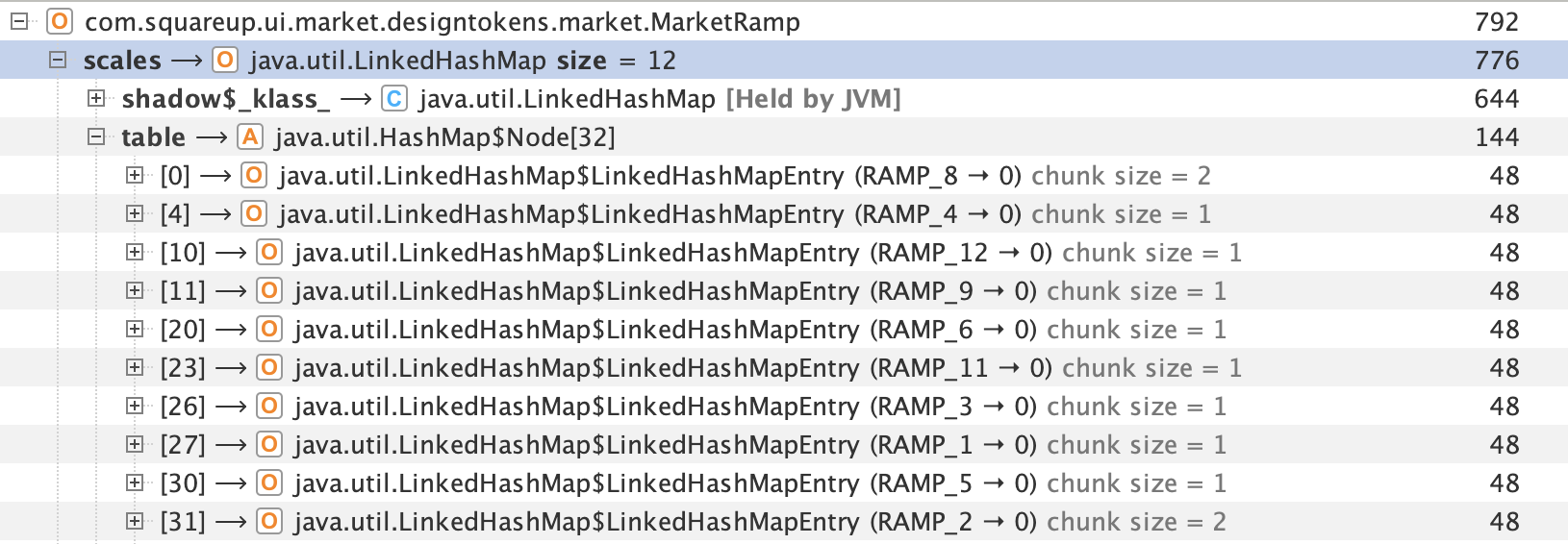
Let's look at the MarketRamp implementation:
kotlin1public enum class SizeRamp { 2 RAMP_1, 3 RAMP_2, 4 RAMP_3, 5 RAMP_4, 6 RAMP_5, 7 RAMP_6, 8 RAMP_7, 9 RAMP_8, 10 RAMP_9, 11 RAMP_10, 12 RAMP_11, 13 RAMP_12, 14} 15 16/** 17 * A definition of the scaling factor set for each [SizeRamp]. This will be the value used by 18 * components to determine their scale based on the selected [SizeRamp]. 19 */ 20public class MarketRamp private constructor(private val scales: Map<SizeRamp, Float>) { 21 22 public constructor( 23 scale1: Float? = null, 24 scale2: Float? = null, 25 scale3: Float? = null, 26 scale4: Float? = null, 27 scale5: Float? = null, 28 scale6: Float? = null, 29 scale7: Float? = null, 30 scale8: Float? = null, 31 scale9: Float? = null, 32 scale10: Float? = null, 33 scale11: Float? = null, 34 scale12: Float? = null, 35 ) : this( 36 mapOf( 37 SizeRamp.RAMP_1 to scale1, 38 SizeRamp.RAMP_2 to scale2, 39 SizeRamp.RAMP_3 to scale3, 40 SizeRamp.RAMP_4 to scale4, 41 SizeRamp.RAMP_5 to scale5, 42 SizeRamp.RAMP_6 to scale6, 43 SizeRamp.RAMP_7 to scale7, 44 SizeRamp.RAMP_8 to scale8, 45 SizeRamp.RAMP_9 to scale9, 46 SizeRamp.RAMP_10 to scale10, 47 SizeRamp.RAMP_11 to scale11, 48 SizeRamp.RAMP_12 to scale12, 49 ) 50 .filter { (key, value) -> 51 value != null 52 } // remove any nulls 53 .mapValues { it.value!! } 54 ) 55 56 public operator fun get(sizeRamp: SizeRamp): Float = scales[sizeRamp] ?: 1f 57}
Nothing here is immediately wrong. We rarely stop to think about the overhead baked into a LinkedHashMap: each entry allocates a separate Node object on the heap, and the map maintains a backing array sized larger than the entry count to keep lookups efficient. For a handful of instances that overhead is negligible — but multiplied across 24,674 of them, it adds up!
How can we optimize this?
The lazy way
1 ▐▛███▜▌ Marcel Code v192.168.0.1 2▝▜█████▛▘ Verse 4.2 · API Usage Billing 3 ▘▘ ▝▝ ~/build/vibe 4────────────────────────────────────────────────────────────────────────────────────────────────── 5❯ CRITICAL: Please use 12x less memory 6──────────────────────────────────────────────────────────────────────────────────────────────────
The fun way
MarketRamp is a map of enum values to floats. Enum values have an int ordinal that reflects their order in the enum declaration. We can use that ordinal as a key in the map, in other words the enum value ordinal can be used as an index into a float array:
kotlin1public class MarketRamp private constructor(private val scales: FloatArray) { 2 3 public constructor( 4 scale1: Float? = null, 5 scale2: Float? = null, 6 scale3: Float? = null, 7 scale4: Float? = null, 8 scale5: Float? = null, 9 scale6: Float? = null, 10 scale7: Float? = null, 11 scale8: Float? = null, 12 scale9: Float? = null, 13 scale10: Float? = null, 14 scale11: Float? = null, 15 scale12: Float? = null, 16 ) : this( 17 FloatArray(SizeRamp.entries.size) { index -> 18 val sizeRamp = SizeRamp.entries[index] 19 val scale = 20 when (sizeRamp) { 21 SizeRamp.RAMP_1 -> scale1 22 SizeRamp.RAMP_2 -> scale2 23 SizeRamp.RAMP_3 -> scale3 24 SizeRamp.RAMP_4 -> scale4 25 SizeRamp.RAMP_5 -> scale5 26 SizeRamp.RAMP_6 -> scale6 27 SizeRamp.RAMP_7 -> scale7 28 SizeRamp.RAMP_8 -> scale8 29 SizeRamp.RAMP_9 -> scale9 30 SizeRamp.RAMP_10 -> scale10 31 SizeRamp.RAMP_11 -> scale11 32 SizeRamp.RAMP_12 -> scale12 33 } 34 scale ?: 1f 35 } 36 ) 37 38 public operator fun get(sizeRamp: SizeRamp): Float = scales[sizeRamp.ordinal] 39}
The array retains only 64 bytes instead of 776 bytes when using LinkedHashMap, that's a 12x size reduction. The total memory footprint went from 19.5Mb to 1.6Mb (~18 Mb
saved).
As a bonus, FloatArray lookups are faster too: a direct index into a primitive array beats hashing, bucket resolution, and unboxing a boxed Float.
Conclusion
When you have a large number of object instances in memory, even small per-instance savings compound quickly. The fixes are often straightforward once you understand the shape of the problem, the hard part is spotting the opportunity. That starts with reading heap dumps... I'm looking into automating that!
And now, let's get back to baking.
