
From Central Data Teams to Data Mesh: Lessons from the Microservices Playbook
As organisations grow, their data needs become more complex. Centralized data teams, which initially serve well, can become bottlenecks, struggling to meet diverse demands from various domains. This evolution mirrors what we saw in software engineering — from monoliths to microservices — now playing out in the data world as a shift towards Data Mesh.
The Challenges of Centralised Data Teams
Centralised data teams often face several challenges as organisations scale:
- Backlogs of data requests: Handling diverse requirements from multiple domains can lead to delays.
- Limited domain context: A central team may lack the specific knowledge needed for domain-specific data tasks.
- Conflicting priorities: Balancing various stakeholder needs can be challenging, leading to slow turnaround on changes and frustrated domain teams that lack visibility.
- Operational overload: Managing on-call duties and incident responses can lead to burnout.
- Scalability pressures: As a company grows, the need to scale quickly becomes critical. But when a central data team is overwhelmed, progress slows. Teams want to fix issues and pay down tech debt — but simply don't have the bandwidth.
- Migration complexity: Ongoing migrations — like moving between the data centres or cloud, adopting new warehouses, or refactoring pipelines — further stretch already limited resources.
Understanding Data Mesh
Data Mesh is a decentralised approach to data architecture. This approach aims to align data ownership with domain expertise, promoting agility and scalability. Instead of a single team managing all data assets, domain teams own and maintain their datasets as data products. It's not just a technical shift — it's a cultural and organisational change, requiring alignment, enablement, and buy-in from leadership.
Ideally, each team is responsible for:
- Producing clean, reliable data
- Making it discoverable and accessible
- Maintaining documentation and contracts
Benefits:
- Data is closer to the people who understand it
- Enables self-service for downstream teams
- Reduces the load on centralised data teams
Challenges:
- Needs good observability and governance tools
- Requires alignment on standards across domains
- Cultural shift: not every team is ready for this added responsibility to own data
Drawing Parallels: Monoliths vs. Microservices and Centralized Teams vs. Data Mesh
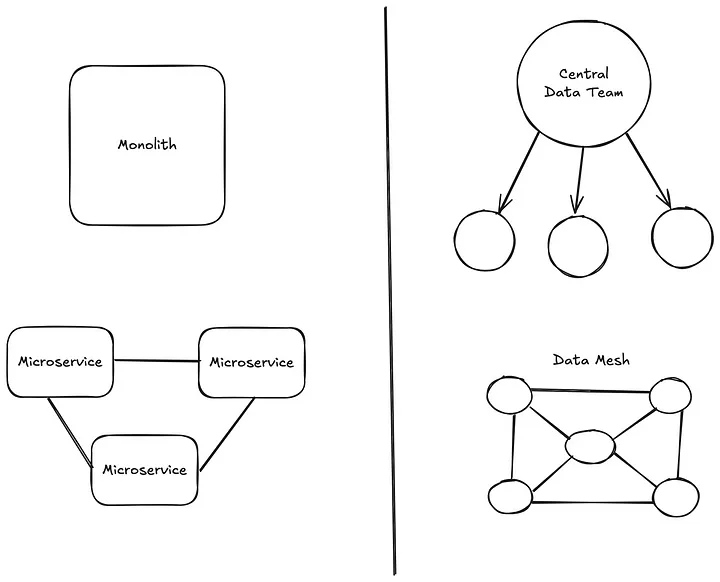
In Software architecture:
| Monolithic Systems | Microservices |
|---|---|
| Centralised control | Distributed ownership |
| Tightly coupled components | Loosely coupled via APIs |
| Single point of failure | Greater resilience through service isolation |
| Slower, complex deployments | Enables continuous delivery |
Parallely, in Data architecture:
| Centralized Data Teams | Data Mesh |
|---|---|
| A single team manages all data | Data ownership lies with domain teams |
| Often becomes a bottleneck | Allows for parallel development and ownership |
| Limited understanding of domain-specific context | Deep domain expertise leads to better data quality and reliability |
| Difficult to scale effectively as organisation grows | More scalable and adaptable to changing needs |
In essence, centralisation offers control but can be less adaptable, while distributed ownership provides flexibility and speed but require strong coordination and governance.
Real-World Implementations
Netflix adopted a Data Mesh architecture for increased flexibility and scale in their data pipelines.
Uber restructured their data platform with a domain-oriented model to decentralise ownership, improve governance, and self-serve infrastructure.
The holistic approach, as demonstrated in case studies, reveals that the benefits of a decentralized, domain-oriented data architecture are contingent upon widespread organizational buy-in and a commitment to consistent data governance practices.
Conversely, they also highlight the potential challenges of a Data Mesh without these crucial non-technical elements that can result in data silos, inconsistencies, and increased complexity. Successful Data Mesh adoption needs a cultural transformation alongside the implementation of global data standards and the underlying technical infrastructure. From a centralized control to domain-oriented ownership inherently involves organizational and cultural change, which is always a non-trivial challenge.
Considerations for Transitioning
Transitioning to a Data Mesh architecture involves both technical and cultural changes. I think some steps to carefully consider:
- Assess Organisational Readiness: Do teams have the technical maturity and support to own their data?
- Invest in Infrastructure: Provide self-serve tools that reduce dependency on central teams.
- Establish Clear Governance: Set standards and policies to maintain data quality and security.
- Foster a Cultural Shift: Encourage product thinking and empower teams to treat data like a first-class citizen.
It's essential to recognise that Data Mesh is not a one-size-fits-all solution. The right approach depends on your organisation's size, complexity, maturity, and long-term goals.
Conclusion
The evolution from centralized data teams to a Data Mesh architecture reflects a broader trend towards decentralisation, mirroring the microservices transformation in software engineering. While centralised models offer consistency and control, they often struggle under the weight of scale and demand. Data Mesh, on the other hand, promises flexibility and speed — but at the cost of added complexity and a need for strong cultural alignment.
This isn't a debate of one being better than the other. It's about understanding trade-offs and choosing what fits best — today and tomorrow. Whether you stick with a centralized model or start exploring Data Mesh, what matters most is that your data architecture is able to evolve in tandem with your organisation's needs.
Acknowledgments
Thank you to Duana Stanley and Minna Yao for their technical reviews and feedback.