
This work builds on prior contributions from engineers across Block who helped establish the foundation for this migration.
Migrating an enterprise-scale React monorepo off an unmaintained UI library taught us to treat AI migrations as validated programs, not giant prompts.
In late 2024, we had to migrate go/console, Block’s internal web platform for deploying and monitoring services, and for building the dashboards teams use to run them, from Base Web to Fluent UI.
This was not a cosmetic refresh. At the start of the product migration phase, the project repo had 11k tracked files, including 10k TypeScript and TSX files. Most of the front-end surface was still tied to Base Web. At the same time, there was no acceptable downtime, no realistic freeze window, and no flag day cutover. Console was a live internal platform, and 40 to 60 engineers were still landing changes in it every day.
So the migration had two jobs at once: move the UI framework forward, and keep the repo moving while the migration was happening.
The pressure was coming from both sides. Uber had already explained that Base Web was scaling back its open source investment and maintenance posture in its post on Open Source Engagement in 2024. React-wise, we were effectively pinned to React 18-era assumptions, which was now in the way of moving to React 19. We could keep carrying Base Web, but we would be carrying it ourselves.
Today, a lot of the techniques in this story sound obvious: selective context, rule-driven validation, AST-based linters, worktrees, targeted tests, temporary migration lanes. In late 2024, they were not. AI tab completion was starting to feel normal, but long-lived coding agents were still barely a concept in day-to-day engineering, and there was no settled playbook for how to run them safely against a large codebase.
The historical framing matters, because we did not start with a grand plan to do this with agents. We started with a migration problem that could not be solved with a freeze window or a weekend refactor. The agentic part became necessary only after it became clear that manual migration alone would be too slow, and naive AI usage would be too unreliable.
Forking Base Web Would Have Been a Trap
Before committing to Fluent, we spent about a month on the question every team asks in this situation: should we just fork the old thing and maintain it ourselves?
We got a Base Web fork building and passing tests the old-fashioned way, by hand. Technically, that proved the point. We could have maintained it.
But that prototype also made the strategic problem obvious.
A working fork would still have left us in the same position:
- tied to a library the ecosystem had moved on from
- responsible for compatibility and future framework work ourselves
- unable to benefit from upstream investment
- still teaching engineers a framework they would use almost nowhere else
It was the wrong kind of maintainable. It would have kept the lights on, but only because we would have become the utility company.
There was also a knowledge cost. Every hour spent getting better at a dead-end framework is an hour spent learning something with very little value outside that codebase. New hires were unlikely to know Base Web. Existing engineers had little reason to want to go deeper on it. We were accumulating highly specific expertise in something the broader ecosystem had already left behind.
We picked Fluent UI because many of its primitives mapped reasonably well to the Base Web primitives we were already using. It was not a drop-in replacement, especially around styling and overrides, but it was close enough that a migration system could be realistic. It also had something Base Web no longer had: clear long-term backing and active investment.
The First Tool Was a TypeScript Server
When this project began in late 2024, the first useful thing we built was not an agent. It was a TypeScript language service and diagnostics server.
Backward as that may sound now, it solved the problem we actually had at the time. We needed fast, local answers to questions like:
- what file should we migrate next?
- what does this symbol resolve to?
- what references and related files matter?
- did the last change break this file?
- did it break the project?
Those are not glamorous questions, but they are the substrate of a safe migration loop.
As the tooling evolved, that server became the core of the migration runtime. It provided definitions, references, diagnostics, file selection, and eventually test execution.
This is one of the places where the historical timeline matters most. If you read the final system first, it is easy to imagine that the agent came first and the tooling came later. In practice, the tooling came first, and then almost immediately we started wrapping it with model-driven orchestration.
Then We Wrapped It in Goose
The first agentic version of the migration system was built around Goose, an early Python-based runtime.
Goose established the basic architecture that the later system kept refining: a long-lived server for TypeScript intelligence, and a separate migrator process that selected files, built prompts, and invoked a model that could call back into the server’s tools.
More importantly, it turned the problem from “ask a model for a rewrite” into “put a model inside a tool-backed loop.” It was still early and rough, but it was already a very different shape from a copy-paste prompt.
Prompts Helped Until They Didn't
Inside that early Goose-based workflow, the obvious thing to try was still basically single-shot prompting: give the model a file, tell it to migrate the file, and let it rip.
That worked just well enough to be dangerous.
The main problem was that model knowledge of Fluent UI was uneven and often stale. The model could generate TypeScript that sometimes compiled cleanly, but still produce code that was not actually good Fluent code. It also struggled with the difference between “syntactically valid” and “semantically correct in a React codebase.”
A recurring example was makeStyles. The model would sometimes create the hook factory inside the component body. TypeScript was happy. React was not. That kind of mistake is exactly what makes large automated migrations look promising in a demo and painful in production.
We also hit a prompt-design wall.
To improve output quality, we started writing component-specific migration hints. For each Base Web component, we documented how its props and behavior mapped to the corresponding Fluent primitive, including examples. That helped. But including all of those hints in every prompt was wasteful. By the time we had built out the hint library, it was already consuming about 25% of a 256k context window before the model had even seen the file it needed to migrate.
In practice, it was a bad trade.
We were spending tokens on irrelevant instructions, and the output was getting noisier as the prompt got broader.
The fix was simple in hindsight: stop prompting globally and start prompting selectively.
We used the TypeScript AST to inspect the file’s import statements and injected only the hints that mattered for that file. If a file imported Button and Tag, it got the Button and Tag hints. If it never touched tables, modals, or selects, it got none of that context.
Small as it sounds, it was one of the biggest quality improvements in the whole effort.
Around the same time, the migration tooling itself was becoming more structured. What started as a focused migration assistant was turning into a platform: explicit project definitions, shared instructions, module hints, and a cleaner split between the long-lived server and the migrator driving it. That mattered because it gave us somewhere to encode product-specific behavior without hard-coding everything into one prompt or one script.
The Rule Engine Made the End State Explicit
Hints improved quality, but they did not solve the deeper problem.
Hints are advisory. A model can ignore them, half-follow them, or apply them inconsistently. What changed the reliability curve was not better prompting. It was making the end state explicit and enforceable.
At the core was a small DSL for import migration rules. A simple example looked like this:
javascript1baseui/button { Button } -> @fluentui/react-components { Button }
As these things tend to go, the DSL evolved from a simple regex parser into a fully fledged ANTLR grammar, which eventually let us express much more complex rules:
javascript1// all import specifiers that have `overrides` could be removed 2glob:"\*\*/\*override\*" { ... } -> \[ null \] \--always 3 4// `Skeleton` from baseui must be replaced by `Skeleton` and 5// `SkeletonItem` from fluent, and all imports from 6// `baseui/skeleton` must be removed 7baseui/skeleton { 8 Skeleton -> @fluentui/react-components { Skeleton & SkeletonItem } 9 ... -> null 10}
These rules did more than document a mapping.
- They told the migration system which files were in scope.
- They constrained what imports the model was allowed to remove or add.
- And because imports had to remain internally consistent, they forced the rest of the file to move toward the new component vocabulary.
The key idea was that import statements gave us a precise, tool-checkable definition of “done.” Because we described how each Base Web component should migrate, we could derive a file-specific subset of rules from the file’s current imports. That gave us a very clear end state for every migrated file.
In practice, this “are we there yet?” guard rail turned out to be the most important check in the whole system.
Every time the model changed a file, we could return specific steering messages:
- this import cannot be removed yet
- this Base Web import must be replaced with that Fluent import
- these new imports are not allowed
- this required binding exists but is still unused
The moment the import changes were correct, the rest of the file started following. If the model added import { Button } from '@fluentui/react-components' but did not use it, TypeScript diagnostics would catch that and push the file further toward the required end state.
We also found that even diagnostic wording mattered. The default TypeScript message for an unused binding nudges the model toward deleting it, which can send the file right back into a failed rule state. Rewriting a message from “Unused variable” to “Unused variable, use it or remove it” made a surprisingly large difference.
The migration stopped being impressive when it worked and started being useful when it failed predictably.
Linters Turned Migration Failures Into Policy
Once the rule system gave us an enforceable end state, the next step was encoding the mistakes the model kept making.
We ended up with more than 50 module-hint files and more than 20 custom linters. That was not prompt bloat for its own sake. It was accumulated operational knowledge from repeated failures.
The linters fell into three broad categories.
Component-Level Correctness
Some checks existed because specific migrated components needed more than just an import swap. A prop might technically be optional but still required for parity. A particular Fluent component might need a specific shape of usage for styling or accessibility reasons.
Framework-Level Correctness
Some checks existed because the model kept generating code that was TypeScript-valid and React-wrong.
makeStyles was the best example. The call must live at module scope because it's a hook factory. That is not an optional style preference. It is part of the framework contract. The linter enforced it.
“Don’t Do That” Correctness
The third category was the one you only learn by watching models in the wild:
- do not add new
as anycasts - do not invent type assertions to silence errors
- do not add obvious comments everywhere
- do not delete existing comments
- do not quietly delete large chunks of code to make a problem disappear
The no-new-comments check was a saving grace. Models in early 2025 loved sprinkling obvious commentary all over the place. Under enough context pressure, they would also find creative ways to “fix” a file by deleting the code that was causing trouble. File-size-change checks were a blunt but effective way to catch that class of failure.
People often skip this part when they talk about AI migrations. The interesting work is not getting the first successful rewrite. It is converting repeated failures into policy so they stop recurring.
Validation Became the Runtime
By this point, we already had diagnostics, prompts, hints, rules, and linters. That still was not enough.
The next bottleneck was feedback speed.
A full tsc --no-emit run on the project took around four minutes. That is survivable for a human. It is brutal for an iterative model loop.
So the next evolution was not adding validation from scratch. It was pulling more validation into the hot path of the runtime.
Instead of waiting on a full-project typecheck after every attempt, the model could edit a file and get near-real-time feedback from the TypeScript language server against the relevant slice of the codebase. Only once the file was locally clean did we spend more on broader validation.
Then tests became part of the contract too.
Starting Jest for even one file in a large monorepo can take 10 to 30 seconds, and that delay becomes expensive when a model keeps running tests after each change. To reduce the startup cost, we kept a Jest process warm in memory and put an RPC layer on top of it. Jest does not really want to be used this way. It has no public APIs of any kind. Making that reliable required wiring together a pile of internal pieces.
By that point, the migration loop had become much more layered:
- migrate a file inside a tool-backed loop
- check import rules
- run linters
- ask the TypeScript server for diagnostics
- run and fix only the related tests when needed
- spend on broader validation only after the file was locally clean
At a high level, the system looked like this:
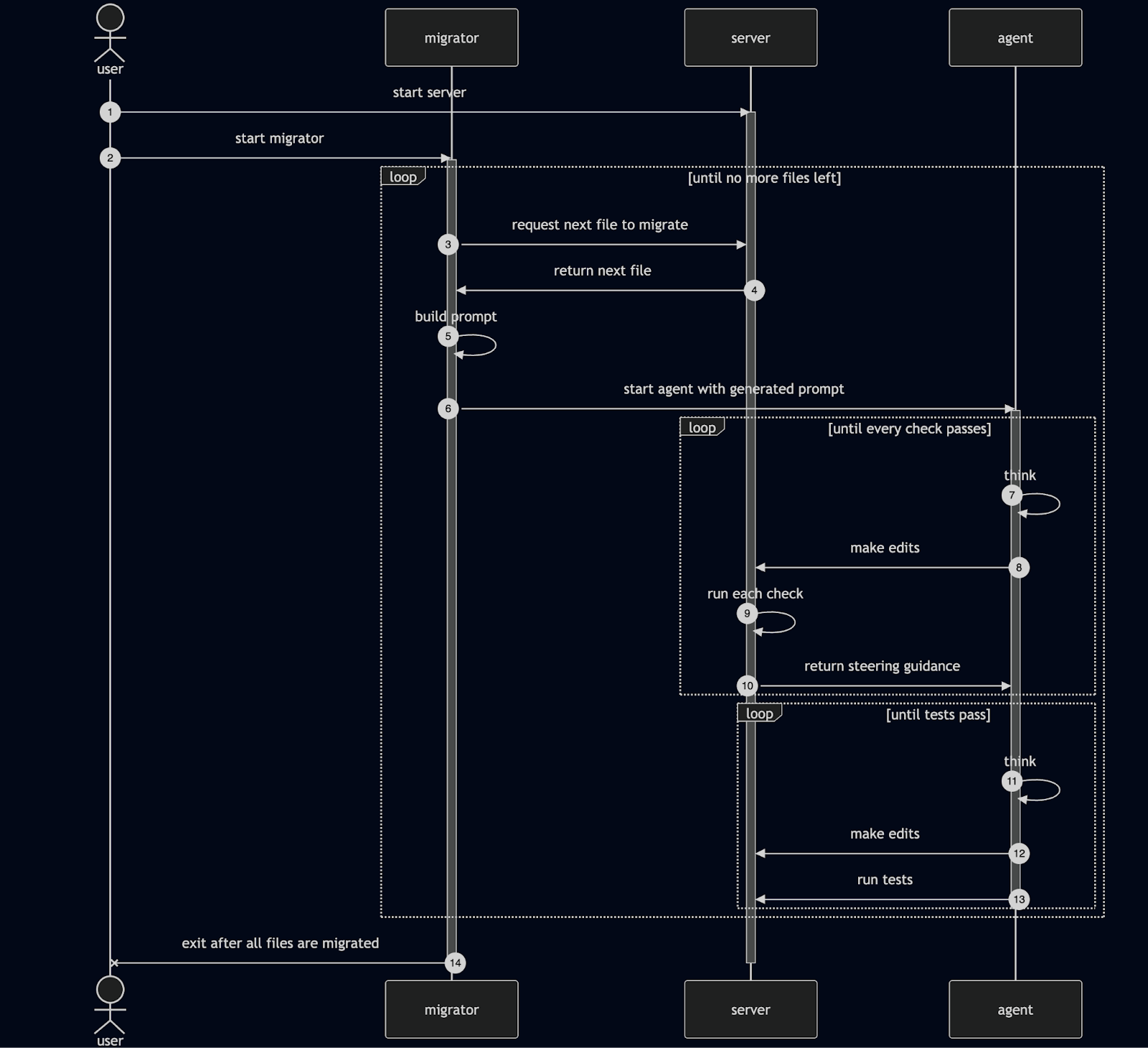
The runtime itself kept changing shape over time. It started as a diagnostics server, quickly grew a Python-based Goose orchestration layer around it, then became a configurable migration platform with project definitions, rules, and tests. After that came a first-party agent runtime, then a TypeScript-native rewrite, and finally the more industrial features people now associate with agentic coding: isolated worktrees, resumable commits, targeted tests, progress tracking, and operational controls for running large migration campaigns. The important point is that each layer was added in response to a concrete failure mode in the previous one.
We Needed a Temporary Migration Lane
The migration engine was only one half of the problem. The product rollout had a separate constraint: we could not stop the world.
Console is a live internal platform. Engineers use it to deploy and monitor services, and teams are shipping into the monorepo every day. A migration that requires weeks of frozen development would never finish. Even worse, without an intermediate state, the migration debt would keep running away from us as new code landed on the old framework.
Which is why we created a temporary Fluent lane inside the repo.
New surfaces could move onto that lane gradually while old ones kept working. Shared providers and host wiring could be updated first. Product surfaces could follow in waves. New code had somewhere to go that was not “please keep adding Base Web while we are trying to remove Base Web.”
By the time the system had fully taken shape, it was really three layers working together:
| Layer | Job |
|---|---|
| Product rollout | Introduce a temporary migration lane, move real surfaces gradually, then remove the scaffolding |
| Product-specific migration layer | Encode component mappings, hints, rules, and linters |
| Shared migration engine | Provide the TypeScript server, runtime, worktrees, diagnostics, and test execution |
That separation also mattered because we wanted to reuse the system for future migrations across the company.
The Rollout Looked More Like a Program Than a Refactor
Once the temporary lane existed, the migration stopped being a theoretical tooling exercise and became a delivery program.
First came platform work: providers, host wiring, landing experiences, and shared foundation code. Only then did the migration turn into a higher-volume rollout across product surfaces. By commit history, more than 80 distinct targets were migrated to Fluent across shared code and product surfaces.
By then, the middle phase looked less like ordinary feature work and more like a factory:
- migrate a surface
- fix styling and behavioral regressions
- rerun tests
- repeat
And like any real migration program, it had exceptions. Some migrations stuck on the first pass. Some did not. A few had to be reverted and redone manually after edge cases surfaced. That was especially true where visual parity, overrides, or product-specific interactions mattered more than raw component substitution.
Put plainly, the agent got us through the bulk mechanics, but humans still had to do the last mile.
The last important step was deleting the scaffolding.
In February 2026, we started collapsing the migration lane back into the steady-state platform. Base Web was removed from the temporary lane and from product surfaces. Large shared areas moved back into the main shared foundation. Then we added lint rules to block direct imports from the migration layer.
That was the correct ending.
The temporary lane existed to make the migration possible. It was never supposed to become the permanent architecture.
Conclusion
The Base Web to Fluent UI migration succeeded because we stopped treating it as a search-and-replace problem and stopped treating the model as the main source of intelligence.
The real leverage came from system design.
We started with a diagnostics server, quickly wrapped it in a Python-based Goose workflow, and then kept hardening the system from there. We made the end state explicit with rules. We converted repeated failures into linters and message rewrites. We pulled validation deeper into the runtime so the feedback loop was fast enough to matter. And because the product could not stop moving, we created a temporary migration lane that let us migrate without downtime or a flag day.
The other lesson is historical. It is easy to read this story in 2026 and think, of course that is how you would run an AI-assisted migration. But when this work began, many of those patterns were not yet common practice. A meaningful part of the effort was not just migrating the codebase, but figuring out what a trustworthy agentic migration even needed to look like.
At this scale, the hard part of an AI-assisted migration is not generating code. It is deciding what the model is allowed to do, how quickly it gets told it is wrong, and how much temporary architecture you are willing to introduce on the way to the steady state.
By the Numbers
The history reads like three phases of the same project.
Pre-Work
Before the first large migration wave hit the product codebase, we had already spent 210 days building the migration machinery and the product-specific rules around it.
- 210 days
- 809 commits
- 4,912 file changes
Actual Migration
Once the temporary Fluent lane existed inside the product codebase, the migration itself ran for 240 days.
- 240 days
- 195 migration-related commits
- 9,801 file changes overall
All Together
From the first migration-engine commit on 2024-12-02 to the cleanup endpoint on 2026-02-26, the effort spanned 451 days, driven primarily by one IC.
Across the tooling, the product-specific migration layer, and the rollout itself, the work adds up to:
- 451 days
- 1,004 commits
- 14,713 file changes
In hindsight, that is the shape of the project: almost as much work went into making the migration possible as went into running it.