

I pushed a change to a core library used by hundreds of Cash App services and waited to see what would break. Ten minutes later I was staring at a green build. I clicked merge, confident that our merge queue would protect against race conditions and keep main stable.
Two years ago, the same change would have required days of coordination across dozens of repositories — publishing versions, updating dependencies, waiting up to an hour for CI — and still risk downstream breakage.
This is the story of how we migrated ~450 Cash App JVM services and libraries into a single monorepo, fundamentally changing how we build, validate, and evolve backend code at Cash App.
To understand how we got here, we need to go back to Cash App’s earliest codebase.
The Square Monorepo
Square historically maintained a monorepo for its Java backend services. When Cash App began as a Square project, its first services naturally lived there.
At the time, Cash App operated largely as a monolith. The primary service, Franklin, contained the majority of the backend code. As Cash App scaled, Franklin grew rapidly — and with it, the strain on the Square monorepo. CI costs increased, build times degraded, and velocity suffered.
At the same time, the Cash App team was interested in exploring alternatives to a monorepo structure. Extracting services into separate repositories promised autonomy and the ability to move quicker.
Both sides saw benefits. Cash App services were split out of the Square monorepo, and the Cash App polyrepo was born.
Cash App Polyrepo
As the name suggests, the Cash App polyrepo consisted of many independent repositories, each with its own codebase. Services and libraries were deeply interconnected, so custom tooling was built to manage dependencies and, when needed, approximate a single-repo development experience.
To reduce release overhead, libraries did not use semantic versioning. Instead, they were versioned using a git SHA and timestamp–based scheme. In theory, this removed the ceremony of publishing releases — tooling would automatically update downstream dependencies.
In practice, it removed the forcing function for backward compatibility.
Breaking changes were routine. Automated updates frequently failed. Teams were left debugging downstream issues they didn’t cause. Over time, some declared “dependency bankruptcy,” ignoring dependency updates entirely because the upgrade cost was too high. Dependencies drifted months or even years behind.
The polyrepo also reinforced a bottoms-up engineering culture. Teams optimized locally, adopting divergent build patterns and conventions. Without shared standards, cross-team contributions became harder, and large-scale changes across the codebase became nearly impossible.
Even small changes could be tedious to propagate, requiring multiple PRs and newly published versions before a change got to where you needed it.
And of course, we had the classic JVM diamond dependency issues: App A depends on lib B and C, which depend on incompatible versions of D.
NoSuchMethodError and NoClassDefFoundError became familiar failures — sometimes caught in CI, and sometimes surfacing as SEVs.
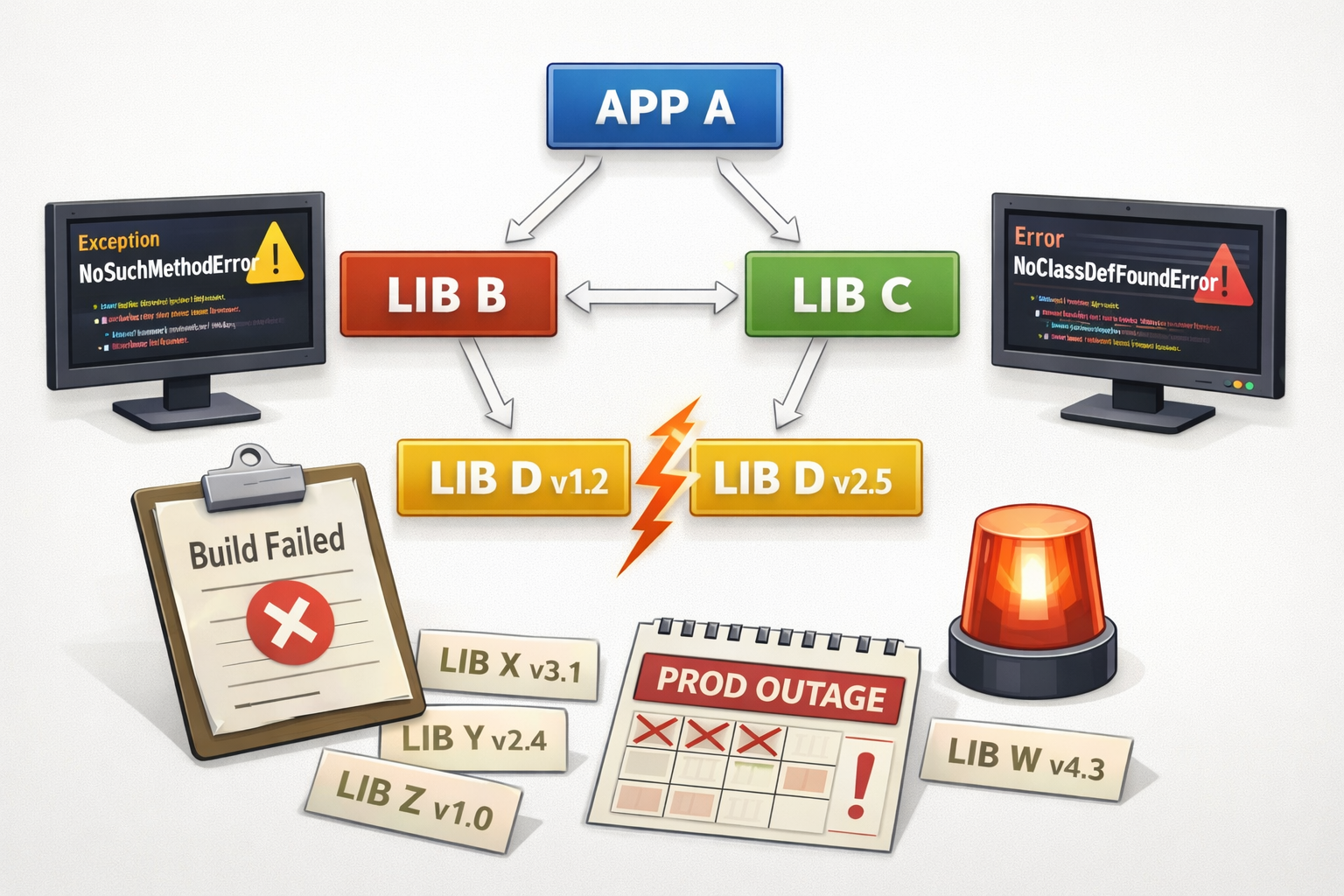
What had once promised autonomy increasingly produced coordination cost and friction.
Monorepo Pilot
We began with a prototype, running scalability and usability tests to validate the approach. Once we were confident the idea was viable, we moved to formal evaluation.
At the time, Cash App engineering was navigating several high-blast-radius architectural decisions. To handle decisions of that scale, we had recently formed a Technical Governance Board (TGB) composed of senior ICs. A monorepo would fundamentally change how hundreds of engineers built and shipped code — exactly the kind of proposal the TGB was meant to assess.
We knew the proposal would face skepticism. Concerns ranged from git scalability and CI load to IDE performance and loss of team autonomy. Rather than walking into a formal review cold, we leaned heavily on nemawashi — building consensus through informal conversations ahead of time. We met with key engineers across teams, surfaced objections early, and pressure-tested our assumptions. In several cases, these conversations reshaped our rollout plan and clarified the safeguards we needed.
By the time we formally proposed the pilot, there were no surprises. The risks were acknowledged, mitigation plans were concrete, and the engineers most likely to be affected had already had a voice in shaping the approach. The TGB approved the pilot, and we partnered with a few willing teams to validate the model in practice.
After seven months of running the pilot and improving the monorepo experience, we were ready to fully commit. We went back to the TGB and got approval for a full rollout.
Monorepo Migration
To support migrations, we built tooling to automate much of the repository import process. In practice, however, many projects required significant upfront work before they were ready to move.
Early on, we made a deliberate decision: this would not be a lift-and-shift migration. Instead, we intentionally used it as leverage to raise engineering standards. Projects were required to meet performance and build quality gates, including sub-10-minute CI, before joining the monorepo.
That meant paying down years of accumulated debt: stale dependencies, divergent build configurations, and inefficient test setups. As build experts, we partnered with teams to fix and optimize their builds, often doing the heavy lifting ourselves to unblock migration. 30-minute builds became 10. Multi-shard test scaffolding — built to compensate for slow pipelines — often disappeared entirely.
Because every project used Gradle, standardization required more than just consolidating code. We invested heavily in shared Gradle plugins to codify conventions, enforce dependency boundaries, and maintain build performance across the monorepo.
We were equally committed to protecting the experience of teams already in the monorepo. When scaling issues surfaced, we paused the migration until they were resolved. This slowed overall progress, but it preserved trust and ensured that quality scaled with adoption.
Over the next 18 months, we migrated the remaining repositories. A few outliers — including Franklin, the original monolith that motivated Cash App’s departure from the Square monorepo — remain outside due to their size and complexity. As the platform continues to mature, we periodically reevaluate whether they can be brought in.
Monorepo Challenges
While the monorepo solved one set of development problems, it introduced new scaling challenges that had to be addressed:
Git Performance
As the repository grew, certain git operations began to slow. Modern git has improved support for large codebases, but even small delays can disrupt developer flow, and expectations for local responsiveness are high. We invested in performance tuning and are exploring approaches like sparse checkouts to ensure local workflows remain fast as the repository scales.
Flaky Tests
In a monorepo, a single change may trigger builds across dozens or hundreds of projects. That scale amplifies the impact of flaky tests — a single flake can block an otherwise valid change. We built tooling to identify and surface the flakiest tests to owning teams, and we’re experimenting with automation and quarantining strategies to keep CI reliable without masking real issues.
Merging to Main Quickly and Confidently
As commit velocity increased, we encountered merge races — changes that were logically incompatible despite merging cleanly. To address this, we adopted merge queues that validate changes sequentially before landing. This significantly improved main branch stability, but during periods of high load the queue can become a bottleneck.
IDE Experience
Large monorepos can strain the IDE experience. Since engineers typically work on a small subset of projects at a time, we developed a custom IntelliJ plugin to support that flow. Engineers now load only what they need, preserving a fast and ergonomic local experience.
Monorepo and AI
When we began this migration, large language models were still emerging and agentic development was not yet part of our workflow. That’s no longer true.
We’re now living through a shift in how code is written and maintained. Agent-generated pull requests are increasing, and cross-cutting refactors that once felt prohibitively expensive are becoming routine.
We don’t yet know what the steady state will look like. But some patterns are already clear.
Having the entire backend codebase in one place allows agents to reason across project boundaries and apply consistent changes without negotiating version graphs or publishing intermediary releases. Shared build conventions and enforced dependency boundaries reduce ambiguity — which benefits both humans and machines.
As agent-driven change volume grows, the bottleneck shifts. Local ergonomics matter less than CI scalability, validation speed, and merge reliability. The same constraints we’ve been investing in — fast builds, reliable tests, safe merge queues — are the foundations that make AI-assisted development viable at scale.
We didn’t move to a monorepo because of AI. But the structural leverage it provides is proving well-aligned with the direction engineering workflows are heading.
What We Would Do Differently
We underestimated how much tooling maturity was required before scaling the migration.
While we built an automated migration tool early on, it required too many manual steps. Those steps slowed progress, introduced errors, and made migrations harder than they needed to be. We didn’t eliminate most of that friction until well into the rollout.
Similarly, we lacked the ability to perform reliable dry-run migrations at the start. As a result, some migrations had to be rolled back after issues surfaced — a poor experience for teams and a drain on momentum.
The same pattern appeared in test reliability. Although our flaky test mitigation is now largely automated, we initially spent significant manual effort containing failures that should have been handled by tooling.
In hindsight, investing earlier in robustness and automation would have accelerated the overall migration and reduced friction for teams.
Conclusion
This story is about more than moving from a polyrepo to a monorepo. It’s about deliberately reshaping our engineering culture and practices.
Moving to a monorepo eliminated entire classes of dependency and coordination problems overnight — no more shepherding changes through chains of repos, no more version drift, no more diamond dependency surprises appearing at runtime. It gave us the ability to make mass changes confidently and keep the dependency graph healthy.
But structure alone wouldn’t have been enough. Without enforced quality gates, strong build tooling, clear ownership, and ongoing investment in developer experience, we would have swapped one set of problems for another. The migration succeeded because we paired structural change with explicit, enforced standards.
Today, with ~8800 builds a week, p90 10-minute CI, and a reliably green main branch, the monorepo is more than a repository — it’s a source of leverage. It allows us to standardize practices, move quickly on cross-cutting improvements, and support the next generation of AI-assisted development with a shared, consistent codebase.
This work was only possible because of an exceptional team. Kartikaya Gupta, Mehdi Mollaverdi, and Tony Robalik held an uncompromising bar for quality and developer experience throughout the migration. I’m grateful to have worked alongside them.