
I'm a huge advocate for software testing and have written and spoken quite a bit about the testing pyramid. Unit tests at the bottom. Integration tests in the middle. UI tests at the top. Fewer tests as you go up, because they're slower, flakier, and more expensive.
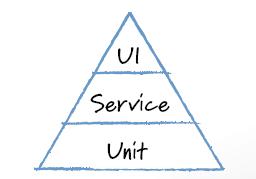
That model worked really well as it gave teams a shared mental model for how to think about confidence, coverage, and tradeoffs. It helped people stop writing brittle UI tests and start investing where it mattered.
But now that I work on an AI agent and have to write tests for it, that pyramid stopped making sense because agents change what "working" even means.
Traditional testing assumes that given the same input, you get the same output.
Agents break that assumption immediately.
LLMs are non-deterministic, agent workflows span multiple steps, tools and extensions live outside our codebase, and sometimes the output is technically correct but still not what you wanted.
Trying to force this into strict pass or fail testing either leads to flaky tests or teams quietly turning tests off.
We needed a different way to think about confidence.
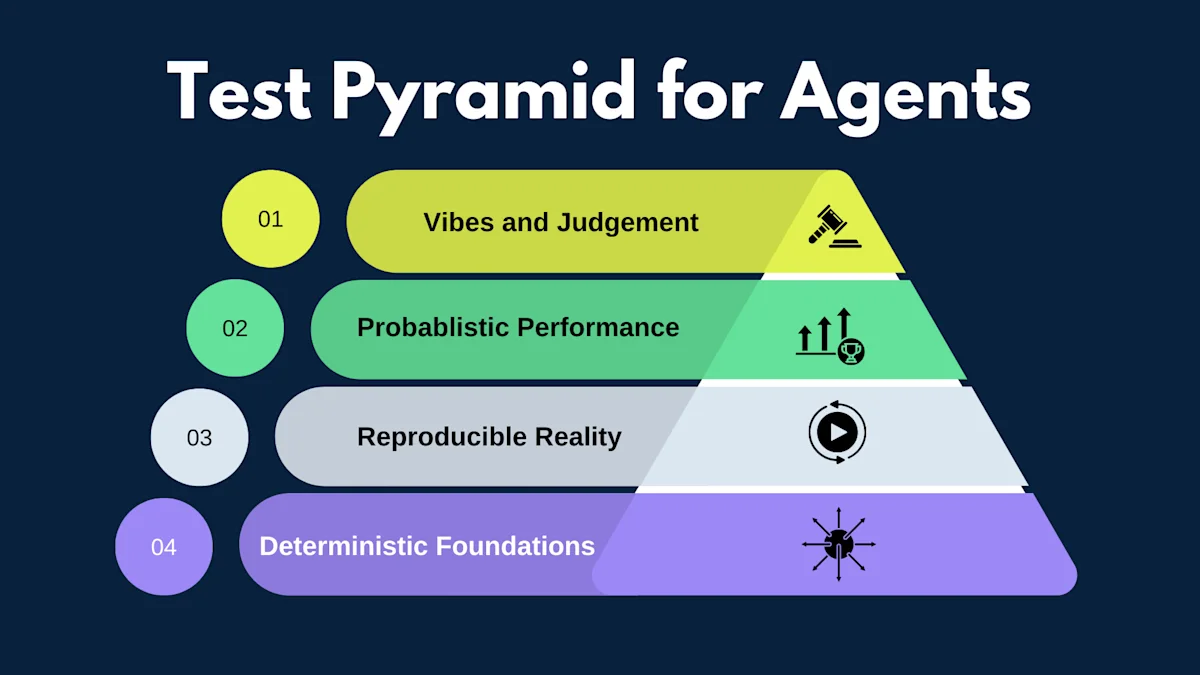
The Agent Testing Pyramid
The biggest shift is that the layers are no longer about test types. Instead, they represent how much uncertainty you're willing to tolerate.
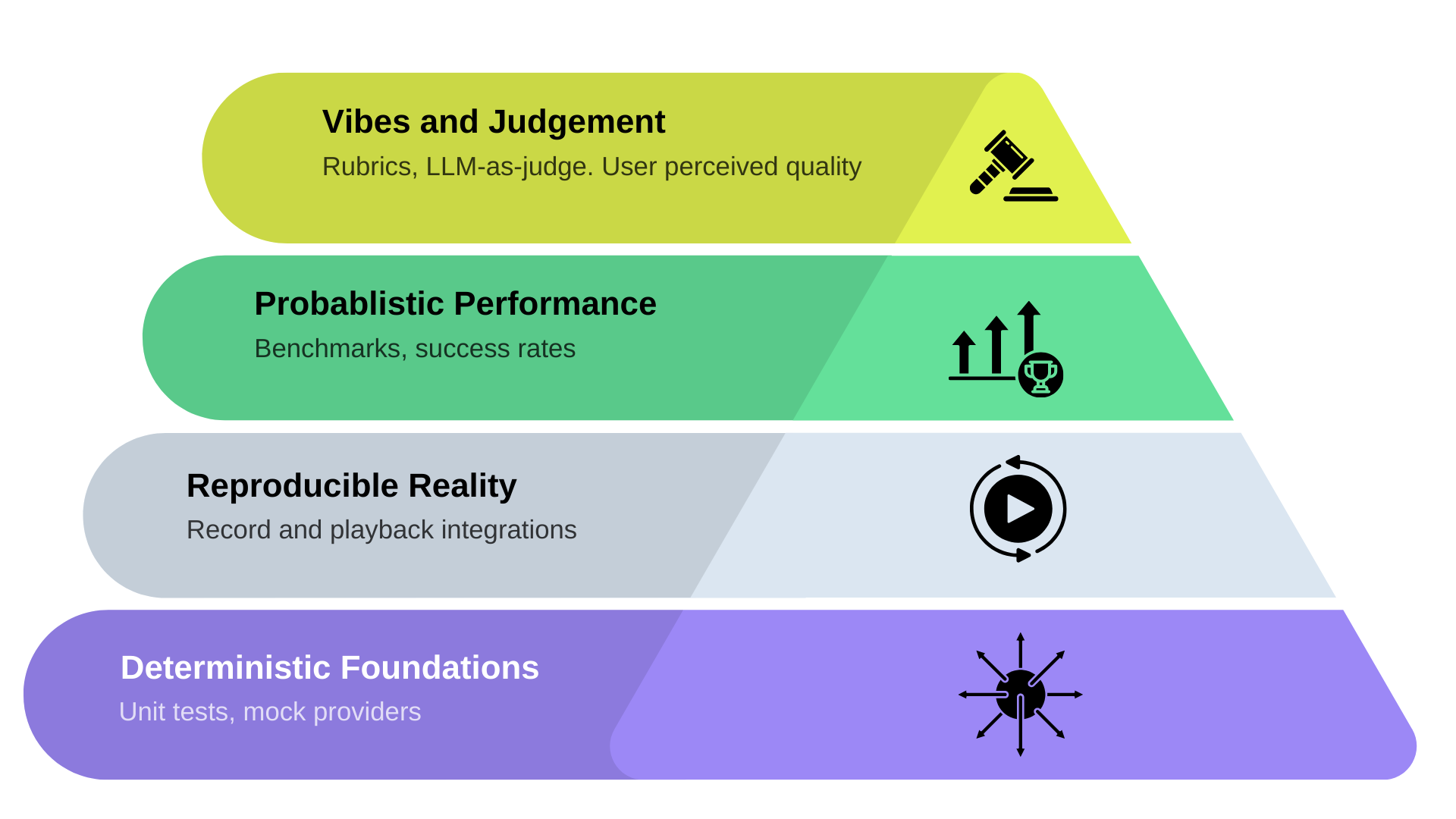
Base Layer: Deterministic Foundations
At the bottom of the pyramid is everything that must be predictable.
We still rely heavily on traditional unit tests here. This includes logic like retry behavior, max turn limits, tool schema validation, extension management, and subagent delegation.
The key difference is how we handle the LLM. Most of these tests use mock providers that return canned responses instead of calling real models. That keeps this layer fast, cheap, and completely deterministic. It also lets us test failure modes that are hard or expensive to trigger with real models.
rust1// Example: Mock that simulates an error 2impl Provider for ErrorMockProvider { 3 async fn complete(...) -> Result<(Message, ProviderUsage), ProviderError> { 4 Err(ProviderError::ExecutionError("Simulated failure".into())) 5 } 6} 7 8// Example: Mock that returns plain text (no tool calls) 9impl Provider for TextOnlyMockProvider { 10 async fn complete(...) -> Result<(Message, ProviderUsage), ProviderError> { 11 Ok(( 12 Message::assistant().with_text("Here's my response"), 13 ProviderUsage::new("mock".into(), Usage::default()), 14 )) 15 } 16}
This layer answers a simple question: Did we write correct software?
If this layer is flaky, we know it's a problem with our software and not AI.
Middle Layer: Reproducible Reality
This layer replaces classic integration tests.
Agents interact with external tools and MCP servers that evolve independently of our code. Mocking them entirely hides real behavior. Calling them live makes tests unstable.
So we record reality once and replay it forever. Funny enough, I used to warn against record and playback for testing, but it's finally found its place.
In record mode, we run real MCP servers and capture the full interaction, including stdin, stdout, and stderr. In playback mode, those exact sessions are replayed deterministically during tests.
We are not asserting exact outputs here. We are asserting tool call sequences and interaction flow.
This lets us verify that the agent uses the right tools, in the right order, and handles responses correctly, without trusting external systems to behave the same way tomorrow.
We apply the same pattern to the LLM itself.
We have a TestProvider that wraps any real provider and can operate in two modes:
- Recording mode: Calls the real LLM, captures the request and response, and saves them to a JSON file keyed by a hash of the input messages.
- Playback mode: Skips the LLM entirely and returns the previously recorded response for matching inputs.
rust1// Recording: wrap a real provider and capture interactions 2let provider = TestProvider::new_recording(real_provider, "fixtures/session.json"); 3let (response, usage) = provider.complete(system, messages, tools).await?; 4provider.finish_recording()?; 5 6// Replaying: no real provider needed, just the fixture file 7let provider = TestProvider::new_replaying("fixtures/session.json")?; 8let (response, usage) = provider.complete(system, messages, tools).await?;
Record a good session, commit the fixture, and now we have a regression test that captures real model behavior at a specific point in time without mocking the content by hand.
This is particularly useful for testing multi-turn conversations where hand-crafting realistic responses would be tedious and error prone.
The tradeoff is obvious: if the model improves, our recorded session won't reflect that. But for testing our code's behavior given some reasonable model output, that's exactly what we want.
Upper Layer: Probabilistic Performance
Some agent behaviors cannot be validated with a single run. This is where we move away from assertions and toward measurement.
We run structured benchmarks that check things like:
- Did the agent complete the task?
- Did it select appropriate tools?
- Did it produce the expected artifacts?
These benchmarks run multiple times and aggregate results. Regression does not mean "the output changed." It means "success rates dropped."
A single run tells us almost nothing but patterns tell us everything.
Top Layer: Vibes and Judgment
This is the layer everyone has, whether they admit it or not.
Summaries, research, explanations, and creative tasks cannot be evaluated with strict equality. So instead of pretending otherwise, we formalize judgment.
We use clear rubrics and another language model as a judge. Each evaluation runs three times, and we take the majority result to smooth out randomness. If all three scores differ, a fourth tie breaker round runs to force a majority.
This turns subjective quality into something we can track and discuss. It doesn't remove judgment, it just makes the judgment explicit and repeatable.
Because let's face it, if we don't test vibes, our users will.
The Agent Tests Itself
There is one more type of test worth calling out: first-person integration testing.
We have a smoke test that we can run ourselves where the agent validates its own capabilities end to end. It creates and modifies files, executes shell commands, discovers extensions, orchestrates subagents, handles errors, and produces a report.
The agent proves it can actually do the things we claim it can do.
If this fails, something real broke.
What This Changes About Testing
Agent testing is probabilistic. That part is non-negotiable. We cannot eliminate uncertainty, but we can manage it.
- Instead of exact matches, we look for trends.
- Instead of pass or fail, we measure success rates.
- Instead of hand waving quality, we judge it explicitly.
But one thing we don't do is run live LLM tests in CI. It's too expensive, too slow, and too flaky. The benchmarking framework runs on demand, not on every pull request. This is a deliberate choice. CI validates the deterministic layers. Humans validate the rest when it matters.
The testing pyramid has evolved. The bottom still matters (probably more than ever), and the top is no longer optional.
Once you accept that, testing agents stops feeling chaotic and starts feeling honest.